
Perkembangan teknologi artificial intelligence (AI) membawa dampak signifikan pada ekosistem internet, termasuk munculnya berbagai bot AI yang aktif melakukan crawling di website. Meskipun beberapa bot memiliki tujuan positif, tidak sedikit yang malah mengganggu performa server. Untuk mengatasinya, Anda perlu memahami cara memblokir bot AI melalui file robots.txt sebagai langkah preventif.
Dalam panduan ini, kami akan menjelaskan cara memblokir bot AI dan bot lain yang tidak diperlukan, sehingga akses terhadap konten orisinal website Anda dapat dikontrol dengan lebih baik. Simak panduan lengkapnya di bawah ini.
Apa Itu Bot AI dan Alasan Perlu Memblokirnya
Bot AI adalah program otomatis yang dirancang untuk mengumpulkan data dari website guna melatih model machine learning atau large language model (LLM). Berbeda dengan bot crawler mesin pencari seperti Googlebot yang membantu melakukan indexing, bot AI seringkali hanya mengambil konten tanpa memberikan traffic balik ke website.
Oleh karena itu, memahami cara memblokir bot AI menjadi langkah penting untuk menjaga kontrol atas konten orisinal dan ide kreatif di website Anda. Berikut beberapa alasan utama mengapa pemblokiran bot AI tertentu perlu dilakukan:
- Perlindungan Konten – Konten orisinal yang Anda buat dengan susah payah bisa digunakan untuk melatih model AI tanpa izin atau kompensasi.
- Konsumsi Resource Berlebihan – Bot AI dapat melakukan ribuan request dalam waktu singkat, membebani server dan memperlambat loading website bagi pengunjung asli.
- Keamanan Website – Beberapa bot tidak diinginkan dapat digunakan untuk mencari celah keamanan atau melakukan scraping data sensitif.
- Mengurangi Trafik ke Website –
Namun, penting untuk selektif dalam memblokir bot karena tidak semua bot merugikan. Bot mesin pencari tetap perlu diizinkan agar website Anda dapat terindeks dengan baik.
Fungsi Robots.txt dalam Mengontrol Akses Bot Website
robots.txt adalah file teks sederhana yang ditempatkan di root directory website Anda untuk memberikan instruksi kepada bot crawler tentang halaman atau bagian mana yang boleh atau tidak boleh diakses. File ini mengikuti standar Robots Exclusion Protocol yang telah disepakati oleh komunitas internet sejak tahun 1994.

Fungsi utama robots.txt meliputi:
- Pengaturan Akses Selektif – Anda dapat menentukan bot mana yang diizinkan atau diblokir, serta halaman spesifik yang ingin dilindungi.
- Optimasi Crawl Budget – Dengan memblokir halaman tidak penting, Anda membantu bot mesin pencari fokus pada konten yang lebih relevan untuk SEO.
- Perlindungan Area Sensitif – Folder administratif, halaman login, atau data pribadi dapat dilindungi dari akses bot yang tidak diinginkan.
- Efisiensi Server – Mengurangi beban server dengan membatasi akses bot yang tidak memberikan nilai tambah.
Perlu dipahami bahwa robots.txt bersifat voluntary compliance. Bot yang baik akan mematuhinya, namun bot jahat (malicious bot) dapat mengabaikan instruksi ini. Oleh karena itu, robots.txt sebaiknya dikombinasikan dengan metode keamanan lainnya.
Dampak Bot AI terhadap Performa dan Keamanan Website
Aktivitas bot AI yang tidak terkontrol dapat memberikan dampak negatif signifikan terhadap website Anda:
- Penurunan Kecepatan Loading – Saat bot AI melakukan crawling masif, server harus memproses banyak request secara bersamaan. Hal ini dapat memperlambat respons server untuk pengunjung manusia, meningkatkan bounce rate, dan menurunkan user interface.
- Peningkatan Penggunaan CPU dan Memory – Setiap request dari bot membutuhkan resource server untuk memproses. Bot yang agresif dapat membuat penggunaan CPU dan memori melonjak hingga 80-90%, bahkan menyebabkan server down.
- Risiko Keamanan Data – Beberapa bot AI dapat mencoba mengakses area yang seharusnya dilindungi, seperti direktori admin atau file konfigurasi. Meskipun kebanyakan bot AI legitimate tidak berniat jahat, data yang mereka kumpulkan bisa saja disalahgunakan.
- Distorsi Analytics – Traffic dari bot AI dapat merusak akurasi data analitik website Anda, membuat sulit membedakan pengunjung asli dengan bot, sehingga keputusan bisnis berbasis data menjadi kurang tepat.
Untuk website dengan traffic tinggi atau yang di-hosting pada server dengan spesifikasi terbatas, dampak ini bisa sangat terasa dan mengganggu operasional bisnis online.
Cara Kerja Robots.txt untuk Memblokir Bot AI
File robots.txt bekerja sebagai “gerbang” pertama yang dicek oleh bot ketika mengakses website. Ketika bot mengunjungi domain Anda, langkah pertama yang dilakukan adalah memeriksa file di lokasi namawebsite/robots.txt.
Proses Kerja Robots.txt:
Bot yang well-behaved akan membaca dan mematuhi aturan yang ditetapkan dalam file ini sebelum melakukan crawling ke halaman lain. File robots.txt menggunakan directive sederhana yang terdiri dari:
- User-agent – Mengidentifikasi bot spesifik yang ingin diatur. Setiap bot memiliki nama user-agent unik yang dapat ditargetkan secara individual atau menggunakan wildcard (*) untuk semua bot.
- Disallow – Menentukan path atau halaman yang tidak boleh diakses oleh bot tersebut.
- Allow – Memberikan pengecualian untuk membolehkan akses ke path tertentu (berguna saat memblokir direktori tapi ingin mengizinkan subdirektori spesifik).
- Crawl-delay – Mengatur jeda waktu antara request bot (tidak semua bot mendukung directive ini).
Prioritas Aturan
Robots.txt mengikuti prinsip most specific rule wins atau dalam bahasa indonesia berarti aturan yang paling spesifik akan dimenangkan. Jika ada aturan yang lebih spesifik untuk suatu path, maka aturan tersebut yang akan diikuti. Aturan juga dibaca dari atas ke bawah, sehingga penempatan urutan penting dalam kasus tertentu.
Keterbatasan
Penting untuk memahami bahwa robots.txt tidak memberikan perlindungan keamanan sesungguhnya. File ini hanya efektif untuk bot yang mematuhi standar. Bot jahat atau scraper agresif dapat mengabaikan instruksi ini. Untuk perlindungan lebih kuat, kombinasikan dengan metode lain seperti rate limiting, firewall, atau deteksi bot berbasis perilaku.
Daftar Bot AI yang Paling Banyak Melakukan Crawling
Seiring berkembangnya teknologi AI, bermunculan berbagai bot yang melakukan crawling untuk mengumpulkan data pelatihan. Berikut daftar bot AI yang paling banyak melakukan crawling pada website.
- GPTBot – Bot resmi dari OpenAI yang mengumpulkan data untuk melatih model GPT. User-agent: GPTBot.
- Google-Extended – Bot Google untuk melatih model AI generatif seperti Bard/Gemini, terpisah dari Googlebot biasa. User-agent: Google-Extended
- CCBot – Bot dari Common Crawl yang mengumpulkan data web untuk berbagai keperluan penelitian dan AI. User-agent: CCBot
- ChatGPT-User – Bot yang digunakan saat ChatGPT mengakses URL yang dibagikan pengguna dalam percakapan. User-agent: ChatGPT-User
- anthropic-ai – Bot dari Anthropic untuk melatih model Claude. User-agent: anthropic-ai
- Claude-Web – Bot Anthropic untuk fitur web browsing Claude. User-agent: Claude-Web
- Omgilibot – Bot untuk agregasi konten dan pelatihan AI. User-agent: omgilibot
- PerplexityBot – Bot dari mesin pencari AI Perplexity. User-agent: PerplexityBot
- Bytespider – Bot dari ByteDance (TikTok) untuk berbagai keperluan termasuk AI. User-agent: Bytespider
- Applebot-Extended – Bot Apple untuk pelatihan model AI, berbeda dari Applebot untuk Siri dan Spotlight. User-agent: Applebot-Extended
- Meta-ExternalAgent – Bot Meta (Facebook) untuk keperluan AI dan machine learning. User-agent: meta-externalagent
Daftar ini terus berkembang seiring munculnya perusahaan AI baru. Sebaiknya Anda memantau log server secara berkala untuk mengidentifikasi bot baru yang perlu ditangani.
Cara Memblokir Bot AI di Robots.txt
Untuk memblokir bot AI di website Anda, silakan ikuti langkah-langkah praktis berikut ini:
Langkah 1: Akses File Robots.txt
- Login ke cPanel hosting Anda.
- Klik menu File Manager, lalu masuk ke /public_html atau sesuai dengan directory root website yang ingin Anda sesuaikan.
- Klik kanan pada file robots.txt, lalu pilih edit.
Jika file robots.txt belum tersedia, Anda dapat membuat file baru dengan nama robots.txt pada direktori tersebut.
Langkah 2: Buat Backup
Sebelum melakukan perubahan, unduh file robots.txt ke komputer terlebih dahulu sebagai backup. Ini penting untuk berjaga-jaga jika terjadi kesalahan konfigurasi.
Langkah 3: Tambahkan Aturan Pemblokiran
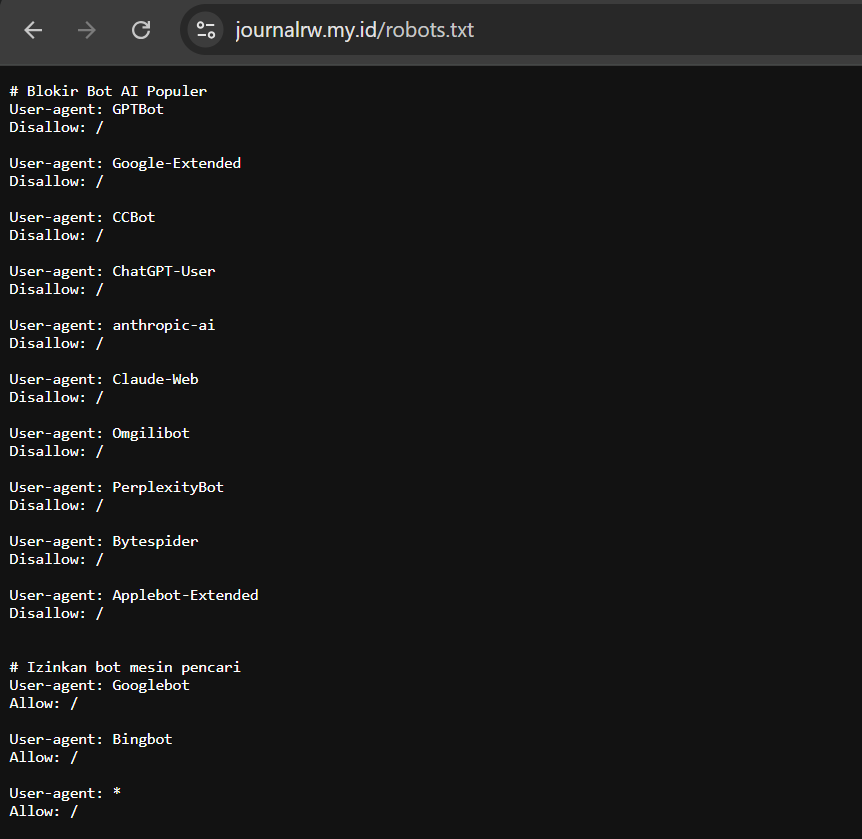
Buka file robots.txt dengan teks editor dan tambahkan kode berikut:
# Blokir Bot AI Populer
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
Catatan: Penggunaan daftar di atas bersifat opsional dan dapat disesuaikan dengan kebutuhan masing-masing website.
Selain itu, pastikan Anda tidak memblokir bot penting seperti Googlebot. Jika ingin mengizinkan semua bot kecuali yang disebutkan di atas, tidak perlu menambahkan aturan khusus. Namun jika Anda sebelumnya memblokir semua bot, tambahkan pengecualian:
# Izinkan Bot Mesin Pencari
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
Langkah 4: Blokir Path Spesifik (Opsional)
Jika Anda hanya ingin melindungi konten tertentu, gunakan path spesifik:
User-agent: GPTBot
Disallow: /artikel/
Disallow: /blog/
Allow: /
Langkah 5: Simpan dan Verifikasi
Simpan perubahan file robots.txt tersebut. Pastikan file berada di root directory website. Setelah itu, akses halaman https://namawebsiteanda/robots.txt di browser untuk memastikan file dapat diakses publik.
Gunakan Robots.txt Tester di Google Search Console untuk memeriksa apakah syntax sudah benar.
Kesalahan Umum Saat Memblokir Bot AI yang Perlu Dihindari
Meskipun konfigurasi robots.txt terlihat sederhana, beberapa kesalahan umum dapat membuat pemblokiran tidak efektif atau bahkan merugikan website Anda:
Memblokir Semua Bot Secara Total
User-agent: *
Disallow: / Menggunakan perintah diatas akan memblokir semua bot termasuk Googlebot, Bingbot, dan crawler mesin pencari lainnya. Ini akan membuat website Anda tidak terindeks sama sekali dan menghilang dari hasil pencarian. Selalu gunakan user-agent spesifik untuk bot yang ingin diblokir.
Salah Syntax
Kesalahan penulisan seperti Useragent (tanpa tanda hubung), spasi ekstra, atau tanda baca yang salah dapat membuat aturan tidak terbaca. Robots.txt sangat sensitif terhadap format penulisan. Pastikan setiap directive ditulis dengan benar dan gunakan validator online untuk memverifikasi.
Tidak Memahami Perbedaan Case Sensitivity
Nilai user-agent tidak case-sensitive, tetapi path URL dalam Disallow bersifat case-sensitive. /Blog/ berbeda dengan /blog/. Pastikan Anda menggunakan kapitalisasi yang sesuai dengan struktur URL website Anda.
Menggunakan Robots.txt untuk Keamanan
Robots.txt adalah file publik yang dapat dibaca siapa saja. Jangan gunakan untuk menyembunyikan halaman sensitif seperti area admin atau data rahasia. Justru dengan mencantumkannya di robots.txt, Anda memberi tahu hacker lokasi tersebut. Gunakan metode autentikasi atau access control yang proper.
Tidak Melakukan Monitoring Setelah Implementasi
Setelah menambahkan aturan pemblokiran, penting untuk memantau log server dan analytics. Periksa apakah bot AI masih muncul, apakah ada bot baru yang perlu ditangani, dan pastikan tidak ada penurunan traffic organik dari mesin pencari.
Penutup
Memblokir bot AI melalui robots.txt merupakan langkah penting untuk melindungi konten website, serta mengurangi beban server. Dengan konfigurasi yang tepat, Anda dapat membatasi akses bot tertentu tanpa mengganggu visibilitas website di mesin pencari. Agar hasilnya optimal, lakukan cek log server secara berkala, update daftar bot, dan selalu lakukan pengujian setelah perubahan konfigurasi.
Untuk mendukung pengelolaan keamanan dan performa website, gunakan infrastruktur hosting yang andal. Rumahweb menyediakan layanan Shared hosting, Cloud Hosting, dan VPS dengan fitur keamanan lengkap, resource yang stabil, serta dukungan teknis 24/7 untuk membantu website Anda tetap aman dan optimal.
Demikian panduan kami tentang cara memblokir bot AI melalui robots.txt, semoga bermanfaat.
