
Aktivitas crawling berlebihan dari bot mesin pencari atau bot tidak diinginkan dapat menyebabkan website mengalami penurunan performa hingga downtime. Kondisi ini seringkali terjadi karena proses crawl yang terlalu intensif menghabiskan resource CPU, RAM, dan bandwidth hosting. Dalam artikel ini, kami akan berbagi cara membatasi akses bot crawling melalui robots.txt secara mudah dan efisien.
Mengapa Perlu Membatasi Akses Bot Crawling
Bot atau crawler adalah program otomatis yang berfungsi untuk mengumpulkan informasi dari sebuah website. Meskipun bot dari mesin pencari seperti Google, Bing dan Yandex membantu website Anda terindeks dan muncul di hasil pencarian, aktivitas crawling yang berlebihan dapat menimbulkan masalah serius.
Berikut adalah beberapa masalah yang sering terjadi, akibat tidak crawling bot yang berlebihan:
1. Konsumsi Resource Server yang Tinggi
Bot yang melakukan crawling intensif dapat menghasilkan ratusan hingga ribuan request dalam waktu singkat. Hal ini menyebabkan lonjakan penggunaan CPU dan memori server, terutama pada paket shared hosting dengan resource terbatas.
2. Penurunan Kecepatan Website
Ketika server sibuk melayani request dari bot, pengunjung asli harus menunggu lebih lama untuk mengakses halaman. Ini berdampak pada user experience dan dapat meningkatkan bounce rate.
3. Risiko Downtime
Dalam kasus ekstrem, aktivitas bot yang sangat masif dapat membuat server kewalahan hingga website menjadi tidak dapat diakses sama sekali (downtime).

4. Bot Jahat dan Scraper
Tidak semua bot memiliki niat baik. Beberapa spider jahat dirancang untuk melakukan scraping konten, mencari celah keamanan, atau bahkan melakukan serangan DDoS.
Dengan membatasi akses bot melalui robots.txt, Anda dapat mengontrol mana yang boleh mengakses website dan mana yang harus diblokir, sehingga resource server tetap optimal untuk melayani pengunjung asli.
Memahami User-Agent Bot Search Engine
User-agent adalah identitas yang digunakan bot untuk memperkenalkan diri saat mengakses website. Setiap bot memiliki user-agent yang unik, yang tercatat dalam log server dan dapat digunakan sebagai basis untuk mengatur akses di robots.txt.
Bot Mesin Pencari Populer
Berikut adalah user-agent dari bot mesin pencari utama yang umumnya perlu diizinkan agar website Anda dapat terindeks dengan baik:
- Googlebot – Bot resmi Google untuk web search. Ini adalah bot paling penting untuk SEO karena Google menguasai lebih dari 90% market share mesin pencari global. User-agent:
Googlebot. - Bingbot – Bot dari Microsoft Bing yang juga digunakan untuk Yahoo Search. Meskipun pangsa pasarnya lebih kecil dari Google, Bing tetap penting terutama untuk pasar Amerika Serikat. User-agent:
bingbot - Slurp – Bot dari Yahoo yang bekerja bersama Bing untuk mengindeks konten web. User-agent:
Slurp - DuckDuckBot – Bot dari mesin pencari DuckDuckGo yang fokus pada privasi pengguna. User-agent:
DuckDuckBot - Yandex – Bot dari mesin pencari Yandex yang populer di Rusia dan negara-negara Eropa Timur. User-agent:
YandexBot
Bot-bot ini umumnya well-behaved dan mematuhi aturan robots.txt dengan baik. Memblokir bot mesin pencari utama hanya disarankan dalam kondisi darurat seperti saat server mengalami overload dan membutuhkan pemulihan cepat.
Bot yang Sering Diblokir
Selain bot mesin pencari, ada banyak bot lain yang sering mengakses website untuk berbagai keperluan. Beberapa di antaranya tidak memberikan nilai tambah dan bahkan dapat merugikan:
- AhrefsBot – Bot dari tool SEO Ahrefs yang melakukan crawling intensif untuk membangun database backlink. Sering diblokir karena aktivitasnya sangat agresif. User-agent:
AhrefsBot - SemrushBot – Bot dari platform SEO Semrush yang mengumpulkan data untuk analisis kompetitor. User-agent:
SemrushBot - MJ12bot – Bot dari Majestic SEO untuk analisis backlink dan authority. Terkenal sangat agresif dalam crawling. User-agent:
MJ12bot - BLEXBot – Bot yang mengumpulkan data untuk analisis web, sering dianggap mengganggu. User-agent:
BLEXBot - Baiduspider – Bot dari mesin pencari China Baidu. Jika target market Anda bukan China, bot ini dapat diblokir. User-agent:
Baiduspider - Ezooms – Bot untuk web crawling dan data mining yang sering menyebabkan beban server tinggi. User-agent:
Ezooms
Memblokir bot-bot ini dapat membantu mengurangi beban server secara signifikan tanpa mempengaruhi SEO website Anda di mesin pencari utama.
Cara Kerja File Robots.txt untuk Membatasi Bot
File robots.txt adalah file teks sederhana yang ditempatkan di root directory website dan dapat diakses melalui URL https://namadomain/robots.txt. File ini mengikuti standar Robots Exclusion Protocol yang telah menjadi konvensi internet sejak tahun 1994.
Prinsip Kerja Robots.txt
Ketika bot mengunjungi website Anda, langkah pertama yang dilakukan adalah memeriksa keberadaan dan isi file robots.txt. Bot yang well-behaved akan membaca instruksi dalam file ini dan mematuhinya sebelum melakukan crawling ke halaman lain.
File robots.txt menggunakan directive sederhana:
User-agent:untuk menentukan bot mana yang diaturDisallow:untuk melarang akses ke path tertentuAllow:untuk memberikan pengecualian aksesCrawl-delay:untuk mengatur jeda waktu antara request (tidak semua bot mendukung)
Robots.txt bersifat voluntary compliance, artinya hanya bot yang mematuhi standar yang akan mengikuti instruksi. Bot jahat atau malicious crawler dapat mengabaikan file ini. Oleh karena itu, robots.txt bukan solusi keamanan yang sempurna dan sebaiknya dikombinasikan dengan metode lain seperti firewall, rate limiting, atau autentikasi server.
File robots.txt juga bersifat publik dan dapat dibaca siapa saja. Jangan gunakan untuk menyembunyikan halaman sensitif karena justru akan memberitahu orang lokasi tersebut.
Cara Mengizinkan Bot Mesin Pencari Merayapi Website
Mengizinkan bot mesin pencari mengakses website adalah langkah penting untuk SEO. Tanpa crawling dan indexing yang proper, website Anda tidak akan muncul di hasil pencarian.
Contoh Aturan Dasar
Berikut cara mengatur file robots.txt dengan aturan yang mengizinkan bot mesin pencari tetapi membatasi area tertentu:
# Aturan untuk Google
User-agent: Googlebot
Disallow: /admin/
Disallow: /private/
Allow: /
# Aturan untuk semua bot lainnya
User-agent: *
Disallow: /admin/
Allow: /Konfigurasi di atas memberikan akses penuh ke seluruh website, kecuali folder /admin/ dan /private/ yang dilindungi dari semua bot.
Penjelasan Syntax
Mari kita pahami setiap elemen dalam konfigurasi robots.txt:
- User-agent: Googlebot – Baris ini menentukan aturan khusus untuk bot Google. Anda dapat menggunakan nama user-agent spesifik (seperti
Googlebot,bingbot) atau menggunakan wildcard*untuk semua bot.
- Disallow: /admin/ – Instruksi ini melarang bot mengakses seluruh isi folder
/admin/dan semua subdirektori di dalamnya. Path harus dimulai dengan garis miring (/) dan bersifat case-sensitive.
- Allow: / – Memberikan izin akses ke root directory dan semua isinya. Directive
Allowberguna untuk membuat pengecualian saat Anda memblokir direktori induk tetapi ingin mengizinkan subdirektori tertentu.
- Komentar (#) – Baris yang dimulai dengan tanda pagar adalah komentar yang tidak diproses oleh bot. Gunakan untuk dokumentasi agar konfigurasi lebih mudah dipahami.
Aturan dibaca dari atas ke bawah, dan aturan yang paling spesifik akan diutamakan. Jika ada konflik, bot akan mengikuti aturan yang paling cocok dengan path yang diminta.
Cara Memblokir Bot Crawling yang Tidak Diinginkan
Ada situasi tertentu di mana Anda perlu memblokir bot, baik secara spesifik maupun menyeluruh. Berikut panduan lengkap untuk berbagai skenario pemblokiran.
Memblokir Bot Spesifik
Jika Anda mengalami masalah dengan bot tertentu yang terlalu agresif, Anda dapat memblokirnya tanpa mempengaruhi bot lain:
# Blokir bot SEO tools
User-agent: AhrefsBot
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: BLEXBot
Disallow: /
# Izinkan bot mesin pencari
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Allow: /Konfigurasi ini secara eksplisit memblokir bot SEO tools yang sering menyebabkan beban tinggi, sambil tetap mengizinkan bot mesin pencari dan bot lainnya mengakses website.
Memblokir Bot dengan Path Spesifik:
Jika Anda ingin melindungi konten tertentu dari bot spesifik:
User-agent: AhrefsBot
Disallow: /blog/
Disallow: /artikel/
Allow: /
User-agent: *
Allow: /Dengan aturan ini, AhrefsBot tidak dapat mengakses folder /blog/ dan /artikel/, tetapi masih dapat mengakses halaman lain di website.
Memblokir Semua Bot (Sementara)
Dalam kondisi darurat seperti server overload, maintenance besar, atau serangan bot, Anda mungkin perlu memblokir semua bot sementara waktu:
# EMERGENCY: Blokir semua bot sementara
User-agent: *
Disallow: /PERINGATAN PENTING: Konfigurasi ini akan memblokir semua bot termasuk Googlebot, Bingbot, dan bot mesin pencari lainnya. Website Anda akan berhenti diindeks dan dapat menghilang dari hasil pencarian jika dibiarkan terlalu lama.
Gunakan pemblokiran total ini hanya untuk kondisi darurat dan jangan lupa mengembalikannya ke konfigurasi normal setelah masalah teratasi. Idealnya, gunakan maksimal 24-48 jam dan pantau Google Search Console untuk memastikan tidak ada dampak jangka panjang pada indexing.
Alternatif yang Lebih Aman:
Jika ingin mengurangi beban server tanpa memblokir total, anda bisa menggunakan command berikut ini.
# Blokir bot non-esensial, izinkan mesin pencari
User-agent: AhrefsBot
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: MJ12bot
Disallow: /
# Tetap izinkan mesin pencari utama
User-agent: Googlebot
Crawl-delay: 10
Allow: /
User-agent: Bingbot
Crawl-delay: 10
Allow: /
User-agent: *
Disallow: /Konfigurasi ini memblokir bot SEO tools dan bot tidak dikenal, tetapi tetap mengizinkan bot mesin pencari utama dengan crawl delay untuk mengurangi beban.
Membuat file robots.txt dan memasangnya
- Buat file robots.txt di direktori utama website Anda.
- Masukan rule User-agents sesuai yang Anda butuhkan, kemudian simpan.
- Setelah itu, akses https://namadomain/robots.txt. Apabila bisa tampil, berarti pemasangannya sudah berhasil.
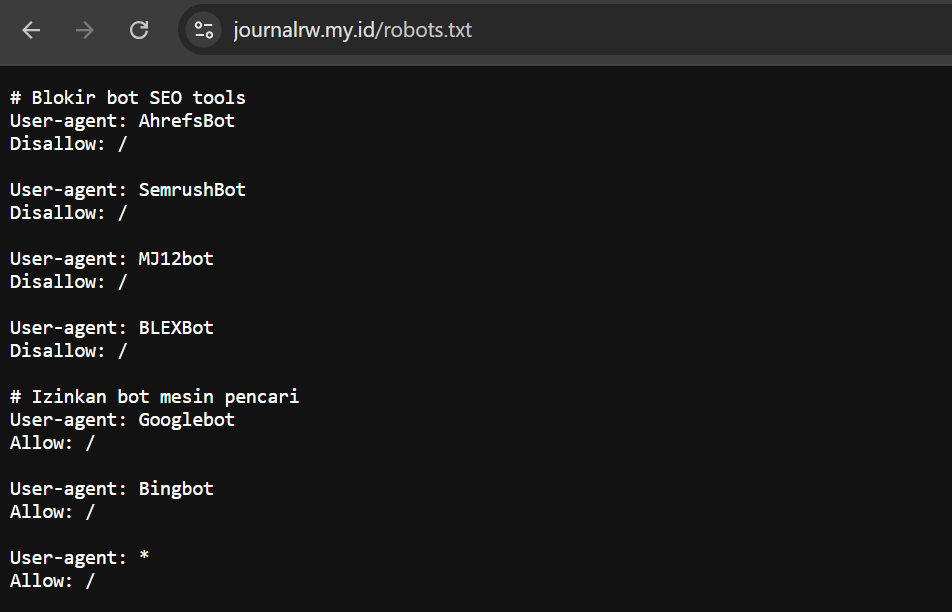
Gambar diatas adalah contoh membatasi akses bot dari beberapa crawler. Anda bisa menyesuaikan script sesuai kebutuhan.
Tips dan Best Practice Membatasi Akses Bot
Untuk hasil optimal dalam membatasi akses bot crawling, ikuti best practice berikut berdasarkan pengalaman kami dalam mengelola website dengan traffic tinggi:
- Jangan Blokir Bot Mesin Pencari Utama – Kecuali dalam kondisi darurat, selalu izinkan Googlebot, Bingbot, dan bot mesin pencari utama lainnya. Memblokir mereka akan berdampak langsung pada SEO dan visibility website di hasil pencarian.
- Gunakan Crawl-Delay dengan Bijak – Directive
Crawl-delaydapat membantu mengurangi beban server dengan mengatur jeda antara request bot. Namun, Google tidak mendukung directive ini. Gunakan Google Search Console untuk mengatur crawl rate Google secara langsung. - Update Daftar Bot Secara Berkala – Bot baru terus bermunculan. Review dan update robots.txt setidaknya setiap 3-6 bulan untuk menambahkan bot baru yang perlu diblokir atau menghapus aturan yang tidak relevan lagi.
- Pertimbangkan Meta Robots Tag – Untuk kontrol lebih granular per halaman, kombinasikan robots.txt dengan meta robots tag di HTML. Meta tag memberikan instruksi spesifik untuk halaman individual seperti
noindex,nofollow, ataunoarchive.
Penutup
Membatasi akses bot crawling melalui robots.txt merupakan langkah efektif untuk mengoptimalkan performa server dan melindungi website dari bot yang tidak diinginkan. Pastikan tetap mengizinkan bot mesin pencari utama agar SEO tidak terganggu, dan kombinasikan dengan monitoring berkala untuk hasil optimal.
Untuk mengelola aktivitas bot secara maksimal, Anda memerlukan infrastruktur hosting yang handal. Rumahweb menyediakan layanan hosting terbaik dengan unlimited bandwidth, proteksi keamanan berlapis, dan dukungan teknis 24/7 yang siap membantu Anda kapan saja.
Demikian artikel kami tentang cara membatasi akses bot crawling di robots.txt, semoga bermanfaat.
