
Ollama LLM adalah salah satu platform open-source yang belakangan ini semakin populer di kalangan developer dan penggemar AI. Dengan Ollama, Anda dapat menjalankan Large Language Model (LLM) seperti Llama 3, Mistral, hingga Gemma secara lokal di komputer atau di layanan VPS secara mudah.
Large Language Model atau yang disingkat menjadi LLM memiliki kemampuan dalam melakukan klasifikasi bahasa melalui pemanfaatan berbagai model pembelajaran. Kemampuan ini memungkinkan LLM untuk mengumpulkan, menganalisis, dan menginterpretasikan data bahasa secara efektif, sehingga dapat menghasilkan keputusan yang relevan.
Dalam praktiknya, kecanggihan yang ditawarkan LLM sering dimanfaatkan dalam berbagai aktivitas di dunia maya, seperti layanan live chat, strategi pemasaran digital (marketing), hingga proses perhitungan dan analisis data yang kompleks.
Dalam artikel ini, kami akan membahas secara lengkap tentang pengertian Ollama LLM, fitur unggulannya, hingga cara membuat dan menjalankannya di VPS agar Anda dapat mulai bereksperimen dengan model AI secara mandiri.
Apa itu Ollama LLM?
Ollama LLM adalah sebuah Large Language Model yang dikembangkan untuk memproses dan menghasilkan teks secara otomatis dengan pemahaman yang mendalam. LLM seperti Ollama banyak digunakan untuk aplikasi seperti chatbot, penerjemah bahasa, analisis teks, dan lain-lain.
Ollama LLM biasanya adalah model yang sudah dilatih dengan data besar dan dapat di fine-tune atau digunakan langsung untuk berbagai tugas NLP (Natural Language Processing).

Fitur Ollama LLM
Ollama memiliki fitur self-host yang memungkinkan Anda untuk menggunakannya secara pribadi ataupun ruang lingkup perusahaan dengan cara menginstalnya secara langsung dalam perangkat PC, laptop, maupun VPS dan melatihnya sesuai kebutuhan.
Dalam panduan ini, kami akan berbagi cara membuat dan implementasi Ollama LLM di layanan VPS, agar fitur ini lebih fleksibel dan dapat diakses darimana saja, termasuk ketika Anda tidak memiliki perangkat pribadi yang kurang memadai.
Sebelum memulainya, Anda harus memahami kebutuhan resource LLM Ollama agar dapat dijalankan dengan baik. Semakin baik model LLM yang ditawarkan Ollama, maka kebutuhan source CPU & RAM juga perlu peningkatan.
Misalnya model deepseek, setidaknya membutuhkan CPU 8 core & RAM 8GB termasuk jika mendukung GPU maka akan lebih baik. Ollama juga menyediakan beberapa model pembelajaran, misalnya llama, deepseek, gpt-oss, tinyllama dan lainnya yang dapat dicek melalui link berikut.
Implementasi Ollama LLM di VPS
Berikut adalah cara membuat dan implementasi Ollama LLM di layanan VPS. Dalam panduan ini, kami menggunakan VPS KVM dari Rumahweb Indonesia.
System Requirements
Dalam demo kali ini, kami akan menggunakan model tinyllama. Opsi ini kami pilih, karena keburuhan source pada VPS tidak terlalu tinggi. Untuk menggunakna model tinyllama, berikut sistem requirements yang dibutuhkan.
- CPU 2 core
- RAM 2GB
- Storage 40GB
- OS Almalinux 9
- Apache & PHP 8.1
- Whitelist Port TCP 11434
Setiap model memiliki kebutuhan sistem (system requirements) yang berbeda-beda. Karena itu, sebelum membuat Ollama LLM, pastikan layanan VPS Anda telah memenuhi spesifikasi sesuai dengan model yang akan digunakan. Setelah semuanya siap, silakan ikuti panduan kami selanjutnya.
Step 1. Install Ollama LLM
Proses instalasi Ollama LLM bisa dilakukan melalui SSH atau terminal di VPS. Silahkan Anda login ke SSH VPS Anda terlebih dahulu menggunakan root akses, lalu anda bisa jalankan perintah berikut:
curl -fsSL https://ollama.com/install.sh | shInstalasi berlangsung cukup cepat, tergantung source VPS yang Anda gunakan.
Step 2. Aktifkan Model Tinyllama
Masih di terminal SSH, jalankan perintah dibawah untuk memilih dan mengaktifkan model LLM:
ollama pull tinyllamaSetelah model LLM aktif, Anda bisa langsung jalankan Ollama dengan perintah dibawah:
ollama serveApabila terdapat informasi bind: address already in use, silahkan memastikannya dengan perintah berikut:
ollama list
Anda akan melihat model tinyllama yang telah running sehingga tidak memerlukan ollama serve.
Step 3. Hubungkan Model Tinyllama dengan Live Chat Sederhana
Anda dapat memanfaatkan Tinyllama sebagai role model AI di live chat. Silahkan ikuti langkahnya hingga selesai.
- Script backend live chat
Berikut merupakan contoh script backend sederhana dengan nama back.php:
- Script frontend live chat
Contoh script frontend dengan nama index.html:
Step 4. Uji Coba Live Chat
Tahap terakhir dari panduan ini dengan melakukan ujicoba secara langsung di browser.
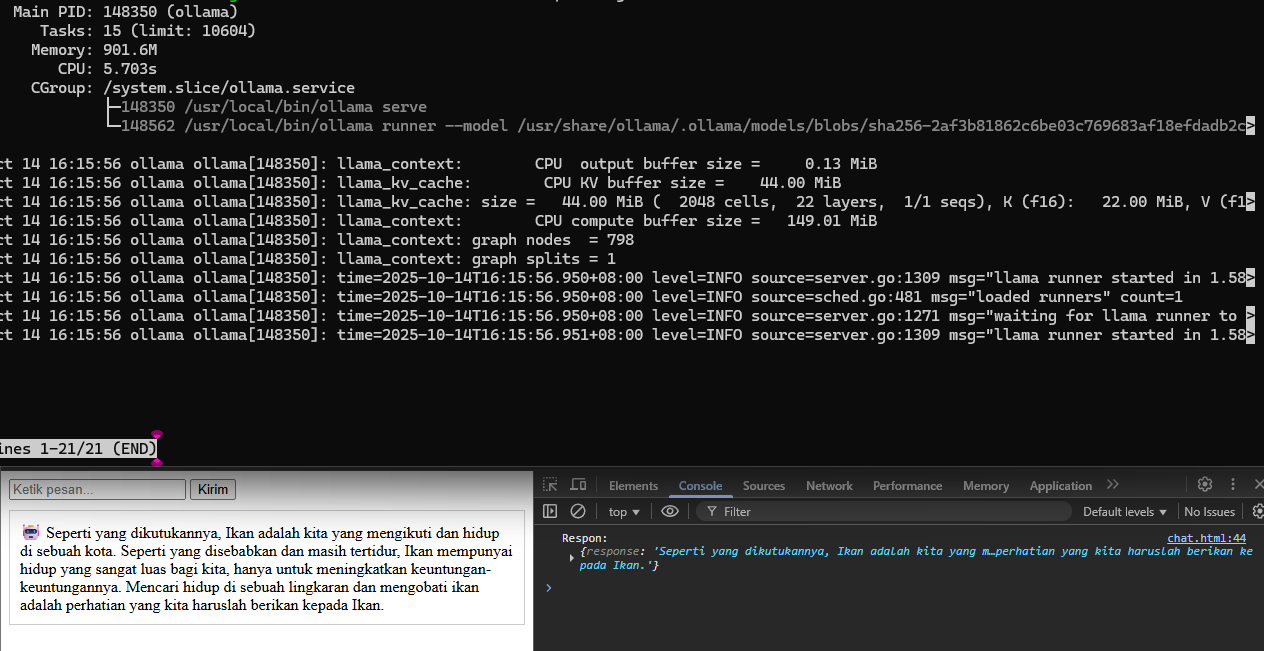
Gambar diatas merupakan contoh dari respon Ollama dengan model Tinyllma.
Untuk tampilan yang lebih modern, Anda dapat menggunakan Open WebUI dan integrasikan ke URL http://localhost:11434/api/generate. Cara install Open WebUI telah kami bahas melalui halaman: Open WebUI
Open WebUI sendiri memerlukan CPU dan RAM minimal 2GB, jadi disarankan VPS Anda memiliki source yang lebih tinggi karena harus memproses model AI dan WebUI secara bersamaan.
Kekurangan Model Tinyllama
Tinyllama adalah salah satu dari sekian model pembelajaran yang disediakan Ollama dengan spesifikasi minimal. Jika sekedar ujicoba, model ini masih bisa Anda gunakan.
Namun, Tinyllma memiliki beberapa kelemahan yang perlu Anda ketahui. Berikut beberapa di antaranya:
- Model lama dengan data minimal: Ukurannya kecil (misalnya 1.1 miliar parameter), TinyLLaMA tidak bisa menyimpan atau mengelola pengetahuan sebanyak model yang lebih besar seperti LLaMA 2 7B atau GPT-3.5.
- Akurasi jawaban: Dengan ukuran yang minimalis dari sebuah mesin learning, TinyLLaMA masih memiliki respon yang dibawah standard dan lebih sering tidak tepat jika digunakan sebagai asisten AI.
- Kemampuan reasoning lemah: Menyebabkan model ini sulit digunakan untuk mode produksi. Anda hanya bisa menggunakan untuk lingkup private karena model TinyLLaMA masih lemah dalam logika, matematika, atau pemrograman.
- Respon yang lamban: Meskipun salah satu model minimalis, TinyLLaMA masih memerlukan source perangkat yang sudah mendukung GPU untuk memberikan tanggapan yang lebih cepat.
TinyLLaMA merupakan salah satu model AI yang tersedia di Ollama LLM. Model ini tergolong ringan dan cocok untuk eksperimen dasar, namun memiliki keterbatasan dalam cakupan pengetahuan sehingga mungkin perlu dilakukan pelatihan tambahan.
Jika Anda membutuhkan performa dan akurasi yang lebih baik, disarankan menggunakan model seperti Deepseek atau GPT, dengan spesifikasi minimal CPU 8 core, RAM 8 GB, serta dukungan GPU yang mumpuni agar proses inferensi berjalan optimal.
Penutup
Dengan mengikuti panduan di atas, kini Anda telah memahami apa itu Ollama LLM, fitur-fitur unggulannya, serta cara membuat dan menjalankannya di VPS. Platform ini memberikan fleksibilitas tinggi bagi Anda untuk bereksperimen dengan berbagai model AI tanpa harus bergantung pada layanan cloud pihak ketiga.
Jika Anda ingin performa terbaik, pastikan VPS yang digunakan memiliki spesifikasi sesuai kebutuhan model LLM yang dijalankan. Selamat mencoba dan semoga panduan ini membantu Anda dalam menjelajahi potensi Ollama LLM lebih jauh!
